Los 4 pilares de una buena prueba unitaria
En este post les voy a compartir 4 aspectos que definen lo que sería una prueba unitaria valiosa, veremos si es posible que exista una prueba unitaria ideal y por último revisaremos conceptos que nos van a ayudar a tener una buena suite de pruebas.
¿Que hace buena a una prueba unitaria?
En post anteriores vimos que existen 3 características claves que hacen de una prueba unitaria una buena prueba unitaria:
- 💻 Tienen que estar integadas en el ciclo de desarrollo.
- 💡 Se debe probar solo las partes importantes.
- 🤔 Deben proveer el mayor valor con el mínimo costo de mantenimiento.
Si bien es fácil entender los primeros 2 puntos, es decir, tenemos que incluir pruebas unitarias cada que desarrollamos nuevas funcionalidades o corregimos bugs, y también tenemos que probar solo las partes más importantes de nuestro sistema, que suele ser la lógica de negocio; nos falta saber ¿Cómo hacer valiosa una prueba unitaria?.
Conociendo los 4 pilares de una buena prueba unitaria
Una prueba unitaria, tiene como pilares o fundamentos lo siguiente:
- 🛡️ Protección contra las regresiones.
- 💪 Resistencia al refactoring.
- ⚡ Rápida retro alimentación
- 🔨 Mantenibilidad
Estos cuatro pilares son fundamentales y se pueden utilizar dependiendo el grado que se tenga de cada uno para analizar cualquier tipo de prueba automatizada.
Protección contra las regresiones
Una regresión es un bug en el software, es cuando una funcionalidad deja de servir como se espera trás una modificación, usualmente cuando se agrega alguna característica nueva.
Una regresión es algo molesto, pero esto no es lo más grave, si no que la realidad del software es que a mayor cantidad de nuevas características agregues, mayores las probabilidades de que aparezcan estos bugs o regresiones.
Un hecho de la programación es que el código no es un documento u objeto si no una responsabilidad.
Por todo lo anterior es que es crucial tener una buena protección contra regresiones, pero: ¿Cómo podemos saber si nuestras pruebas ofrecen una buena protección contra regresiones?. Para ello hay que tener en cuenta los siguientes puntos:
- 📝 La cantidad de código que se ejecuta durante la prueba
- 🕹 La complejidad del código que se está ejecutando
- 👓 La significancia del código ejecutado
Generalmente a mayor cantidad de código de tu sistema es ejecutado en una prueba tiene mayor oportunidad de revelar una regresión, sin embargo, no solo es ejecutar código por ejecutarlo, si no que también entra en juego la complejidad del código y la importancia que tenga para el problema que estás resolviendo.
1 class Animal { 2 constructor(name, type, age) { 3 this.name = name; 4 this.type = type; 5 this.age = age; 6 } 7 get name() { // ⚪️ Solo es un método con lógica muy simple 8 return this.name; 9 } 10 // ⭐️ Tiene más significancia y más complejidad para la clase Animal 11 humanAge() { 12 if (this.type === "DOG") return this.age * 7; 13 return this.age * 3; 14 } 15} 16
Por último es importante saber que todo el código que no escribes como las librerías o frameworks que utilizas también cuenta y se debe incluir para esta protección contra regresiones.
Para maximizar la protección contra regresiones, las pruebas deben ejecutar la mayor cantidad de código posible tomando en cuenta la significancia que tiene para tu aplicación.
Resistencia al refactoring
El segundo pilar es la resistencia al refactoring, que es el grado que puede soportar una prueba tras haber ocurrido un refactoring del código que está probando, sin que la prueba falle.
Refactoring: Es modificar el código existente sin alterar su comportamiento observado, estas modificaciones son para mejorar la calidad del código, para que sea más legible, simple, etcétera…
Supongamos que acabamos de hacer una nueva funcionalidad que esta trabajando correctamente, no rompe nada y las pruebas pasan, después de esto decidimos mejorar o limpiar el código, tras hacerlo todo sigue funcionando a la perfección, el código se ve mejor, pero las pruebas comienzan a fallar 😱.
En el enunciado anterior vemos claramente lo que es la resistencia al refactoring en las pruebas, para ese ejemplo en específico las pruebas no tuvieron resitencia al refactoring.
Cuando todo funciona bien y como se espera, pero las pruebas fallan, producen algo conocido como falsos positivos.
Como ya vimos, el objetivo de las pruebas unitarias es habilitar el crecimiento sostenible de un software, esto significa poder agregar nuevas características y refactorings de manera regular, reduciendo al mínimo la introducción de bugs o regresiones.
La pruebas unitarias ofrecen una advertencia temprana de que se rompió algo y la confianza de agregar nuevas características sin introducir bugs; sin embargo, los mencionados falsos positivos diluyen estos beneficios:
- 💀 Si las pruebas dan muchos falsos positivos se pierde la capacidad de reaccionar a los problemas legítimos que sucedan, por que no sabrás si las pruebas estan fallando por una buena razón o no.
- 😪 Se pierde la confianza de agregar nuevas caracterísitcas o refactorings por el temor que pueden infundir estas falsas alarmas, muchas veces los programadores prefieren no tocar el código.
¿Qué produce los falsos positivos?
El número de falsos positivos que genera una prueba está directamente relacionado con como está estructurada, si una prueba esta altamente acoplada con la implementación del sistema bajo pruebas, mayor cantidad de falsos positivos tendrá.
Por el contrario una prueba debe verificar el resultado final que el sistema bajo pruebas entrega, es decir, su comportamiento observable, y no los pasos o la implementación que sigue para llegar a el.
Entendamos mejor con el siguiente ejemplo, está divido por pestañas, la primera es el sistema bajos pruebas: rendermarkdown.js, y en las siguientes pestañas son una manera incorrecta y una correcta de escribir la prueba:
rendermarkdown.js: Este es nuestro sistema bajo pruebas, es una clase que se encarga de crear un mensaje en markdown muy simple.
1// rendermarkdown.js 📂 2class RenderMarkdown { 3 renderTitle(message) { 4 return `#${message}`; 5 } 6 renderSubtitle(message) { 7 return `##${message}`; 8 } 9 renderParagraph(message) { 10 return message; 11 } 12 render(message) { 13 return ( 14 this.renderTitle(message) + 15 " " + 16 this.renderSubtitle(message) + 17 " " + 18 this.renderParagraph(message) 19 ); 20 } 21} 22
bad test ❌ : Esta es una manera incorrecta de estructurar la prueba por que estamos acoplando a la implementación del método render en lugar del resultado final, aumentando mucho la probabilidad de falsos positivos y haciendo la prueba no resistente al refactoring.
1// BAD TEST ❌ 2it("The markdown is generated correctly", () => { 3 // Arrange 4 const spyRenderTitle = jest.spyOn(RenderMarkdown.prototype, "renderTitle"); 5 const spyRenderSubtitle = jest.spyOn( 6 RenderMarkdown.prototype, 7 "renderSubtitle" 8 ); 9 const spyRenderParagraph = jest.spyOn( 10 RenderMarkdown.prototype, 11 "renderParagraph" 12 ); 13 const markdownRender = new MarkdownRender(); 14 // Act 15 markdownRender.render("x"); 16 //Assert 17 expect(spyRenderTitle).toHaveBeenCalled(); 18 expect(spyRenderSubtitle).toHaveBeenCalled(); 19 expect(spyRenderParagraph).toHaveBeenCalled(); 20}); 21
¿Que pasaría si decidimos renombrar el método de renderTitle por renderHeader?: Nuestra prueba fallaría al instante aunque el resultado final que es el mensaje en markdown no cambie, lo mismo si lo hacemos con los otros métodos.
good test ✅ : A diferencia de la prueba anterior en esta se verifica el resultado(comportamiento) esperado del método render, así de esta manera no importan los cambios internos o refactorings que se le hagan a los pasos o al resto de métodos para llegar a el, siempre y cuando el resultado sea correcto.
1// GOOD TEST ✅ 2it("Render markdown message", () => { 3 //Arrange 4 const message = "x"; 5 const markdownRender = new MarkdownRender(); 6 // Act 7 const markdownMessage = markdownRender.render(message) 8 // Assert 9 expect(markdownMessage).toBe('#x ##x x'); 10}); 11
La conexión entre los primeros 2 pilares y la precisión de las pruebas
Existe una conexión entre los 2 primeros pilares, la protección contra regresiones y la resistencia al refactoring, ya que los dos determinan el nivel de presición de las pruebas.
Para entender mejor que es la presición en las pruebas unitarias, les comparto una tabla muy similar a la del libro y la explico a continuación:
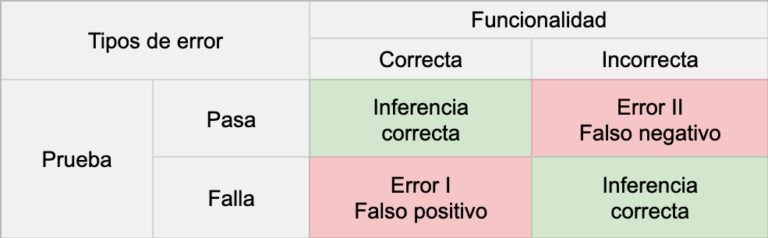 Presición en las pruebas
Presición en las pruebas
✅ Cuando tienes una funcionalidad correcta y además la prueba que lo verifica pasa, la prueba demuestra bien el estado del sistema, que en este caso no presenta bugs al estar funcionando correctamente.
✅ Cuando la funcionalidad se rompe, y la prueba que lo verifica falla, se hace la detección oportuna del bug o regresión, es decir, si nuestra funcionalidad deja de servir apropiadamente, se espera que la prueba falle.
Hasta ahora hemos explicados los dos condiciones correctas, si embargo como vemos en la tabla en rojo, hay dos situaciones incorrectas que bajan o quitan la presición de las pruebas.
❌ Cuando nuestra funcionalidad es correcta pero la prueba falla, obtenemos un falso positivo, suele suceder tras realizar un cambio al código que no modifca el comportamiento observado (refactorign), aquí es donde nos ayuda el pilar de resistencia al refactoring.
❌ Cuando la funcionalidad esta rota pero la prueba pasa, es un falso negativo, quiere decir que la prueba no es capaz de detectar el mal funcionamiento o bug, desproveyendonos de la protección contra regresiones.
En conclusión, la presición de una prueba esta determinada por :
- ⚙️ Que tan buena es la prueba de indicar la presencia de bugs (ausencia de falsos negativos – protección contra regresesions).
- ⚙️ Que tan buena es la prueba de indicar la ausencia de bugs(ausencia de falsos positvos – resistencia al refactorign)
Podría parecer que los falsos negativos, son los peores, sin embargo a la larga, los falsos positivos demeritan totalmente las bondades que puede tener una suite de pruebas.
Los últimos pilares: rápida retro alimentación y la mantenibilidad
Los dos pilares restantes son dos características de las que ya hemos hablado, la rápida retro alimentación y la mantenibilidad, para medirlas se nesecita considerar lo siguiente:
- 🔨 Mantenibilidad: que tan fácil son de entender las pruebas, generalmente a menor cantidad de líneas tengan es más fácil de entender, pero esto no significa que debamos reducir nuestas pruebas de una manera forzada, hay que tratar las pruebas como lo que son, algo importante.
- ⚡️ Rápida retro alimentación: Que tan dfícil es correr las pruebas, aquí influyen factores como el tiempo de espera para ver los resultados, si tienes que levantar x o y instancia, etcétera.
La rápida retro alimentación es importante por que puede alentar o desanimar el que ejecutes las pruebas, a si mismo, la mantebilidad en las pruebas nos ayuda a estar teniendo una suite de pruebas sana de manera fácil.
¿Existe la prueba ideal?
La respuesta corta es NO, porque siempre va existir un trade off entre los pilares de : protección contra regresiones, resistencia al refactoring y la rápida retro alimentación.
Cuando realizamos una prueba siempre se va a sacrificar algo de uno de los 3 pilares mencionados, el pilar de la mantenibilidad no está correlacionado con los anteriores.
Para entender mejor esto veamos la siguiente lista de ejemplos:
- 📝 En una pruebna end-to-end se ejecutagran cantidad de código ya que se verifica desde el más bajo nivel hasta lo que se le presenta al usuario, por lo cual ofrecen una gran protección contra regresiones, pero el hecho de abarcar varios módulos hace que tengan una lenta retro alimentación.
- 🍷 Otro caso es cuando haces una prueba unitaria frágil, es decir, muy acoplada a la implementación dejando de lado la resistencia al refactorign, pero teniendo una buena protección contra regresiones ya que detectará de inmediato un bug.
- 🍞 Por último otro caso es cuando realizas pruebas triviales, cuando pruebas comportamientos extreamandamente simples, son pruebas altamente rápidas y resistentes al refactorign pero no proveen ninguna protección.
Para el caso de las pruebas unitarias la resistencia al refactorign no es negociable, se tiene o no se tiene, por ello, con lo que se tiene que jugar es entre la protección contra regresiones y la rápida retro alimentación.
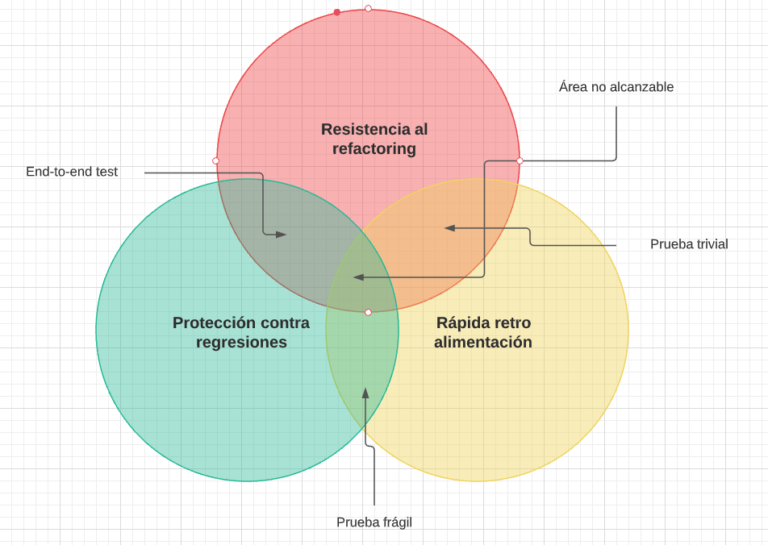 Diagrama de venn de: pilares de las pruebas unitarias
Diagrama de venn de: pilares de las pruebas unitarias
En mi punto de vista personal creo que lo mejor es tener el máximo de protección posible trantando de disminuir lo menor posible la rápida retro alimentación.
Conceptos de automatización Hablaré solo de dos conceptos de automatización de manera breve: las pruebas de caja negra y las pruebas de caja blanca:
- ⬜️ Las pruebas de caja blanca verifican la aplicación internamente, es decir, se realizan tomando el cuenta el código y la implementación, se enfocan en como lo hace.
- ⬛️ Las pruebas de caja negra verifican el resultado esperado o lo que se supone que la aplicación tiene que hacer sin tomar en cuenta el como lo hace o la implementación.
Podemos darnos cuenta que las pruebas de caja blanca nos van a quitar la resistencia al refactoring y que debemos tomar por defecto la caja negra como método para realizar nuestras pruebas unitarias, sin embargo, todavía se puede utilizar el método de caja blanca para analizar las pruebas y otras métricas.
Por ejemplo cuando estamos analizando el code coverage o branch coverage es necesario conocer como esta implementada la aplicación, incluso también la caja blanca nos sirve para analizar el como se comporta una pieza de la aplicación para determinar el resultado esperado.
Lo mejor es utilizar una combinación de ambos métodos.
Entraré en más detalle en próximos capítulos de este post que es un resumen y mi entendimiento del libro:
📖 Unit testing: principles, pratices and patterns” por Vladimir Khorikov de la editorial Manning.