Mocks y fragilidad en las pruebas
A lo largo de este post conoceremos, más a detalle los mocks y los otros tipos de test doubles, también veremos como los mocks están relacionados con la fragilidad en las pruebas.
Como ya vimos en el primer post de esta serie: La meta de las pruebas unitarias, existen dos corrientes o escuelas para crear pruebas unitarias, en resumen ambas escuelas difieren por la forma en que se deben aislar las pruebas, ambas a través de test doubles que eliminan las dependencias.
En muchos casos se dice que el uso de mocks solo hace más frágiles tus pruebas, pero esto no siempre es así, muchas veces también el uso de mocks es preferible.
Diferencia entre mocks y stubs
Hasta ahora a lo largo de los posts hemos mencionado los mocks y los tests doubles en general, un mock es un tipo de test double, pero existen otros, por ejemplo: stub.
Test double es un término general que proviene de la noción de los dobles de prueba o de acción en las películas, hay varios tipos.
En general, uno de los usos más comunes es facilitar las pruebas, nos ayudan a sustituir las dependencias, evitando así la complejidad que pueden tener las reales y principalmente poder aislar lo que estamos probando.
De acuerdo a Gerard Meszaros existen 5 variaciones de test doubles:
- 🤡 Dummy
- 🤖 Stub
- 👺 Fake
- 😎 Spy
- 👾 Moc
Pero podemos categorizarlos en 2 grandes grupos:
 Clasificación de los test doubles
Clasificación de los test doubles
La diferencia princiál entre los mocks y los stubs es la siguiente:
- 🤖 Stub: Ayuda simular interacciones de entrada, es decir, llamadas que el SUT hace a sus dependencias para obtener información de entrada para realizar alguna operación.
- 👾 Mock: Sirve para simular y analizar interacciones de salida, es decir, son llamadas que el SUT hace a sus dependencias para que cambien su estado, es decir devienen en un side effect.
Para que se usa un mock vs un stub
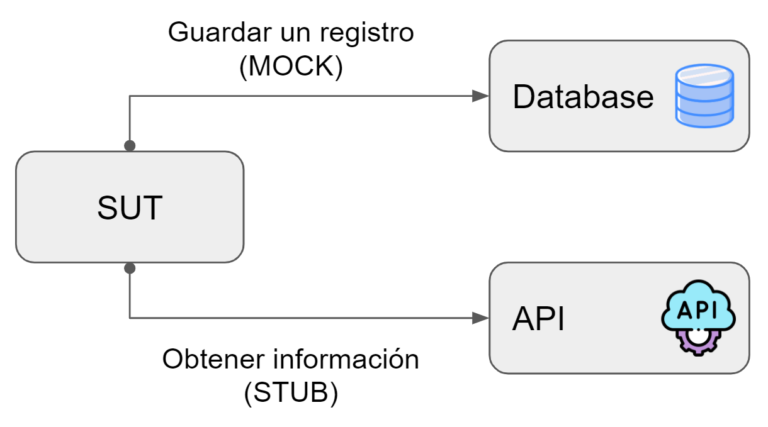 ¿Como usar los mocks vs stubs?
¿Como usar los mocks vs stubs?
Internamente dentro de cada una de las 2 grandes categorías que mencionamos, empezando por los mocks, a diferencia de lo que dice el libro, yo pienso que la diferencia entre un mock y un spy es que el mock tu puedes construir la forma de emular el comportamiento mientras que un spy está al pendiente o copia como tal el comportamiento de la dependencia real.
En cuanto a los stubs, dummies y fakes la única diferencia son detalles de implementación y el nivel de complejidad con el que se construye, siendo el dummy el más simple ya que puede ser desde un dato en duro como una cadena de texto hasta un objeto vacío sin comportamiento solo para satisfacer la entrada requerida.
Un fake por otro lado es el siguiente nivel de complejidad y se usan para remplazar dependencias que se generan durante la ejecución.
Por último un stub suele ser el más complejo ya que puede ser configurado para agregarle comportamientos que satisfaga distintos escenarios.
Mock(el test double) vs Mock(la herramienta)
El término mock se ha sobrecargado mucho, tanto así que suele ser utilizado como sinónimo de test double, sin embargo este solo es un tipo de test double, asimismo, en muchos frameworks nos encontraremos que las herramientas para crear test doubles contienen la palabra “mock” pero no siempre son utilizadas para crear mocks como tal, si no para crear stubs también.
Ejemplos:
1// MOCK 2public class Tests { 3 @Test 4 public void an_example_test(){ 5 // Arrange 6 Database database= mock(Database.class); // mock la herramienta 🔨 7 // database es un mock creado con dicha herramienta 👾 8 when(database.saveUser("user@test.com","Jhon")) 9 .thenReturn(new User(1,"user@test.com","Jhon")) 10 UserController sut = new UserController(database); 11 // Act 12 sut.register("user@test.com","Jhon"); 13 // Assert 14 verify(database, times(1)).saveUser() 15 } 16 17} 18
1// STUB 2public class Tests { 3 @Test 4 public void an_example_test(){ 5 // Arrange 6 Country[] countries = new Country[1]; 7 countries[0] = new Country("Mexico") 8 CountriesApi api = mock(CountriesApi.class); // mock la herramienta 🔨 9 // un stub 🤖 generado a través de la herramienta mock 10 when(api.getAvailables()).thenReturn(countries) 11 UserController sut = new UserController(api); 12 // Act 13 sut.doSomething() 14 // Assert 15 assertEquals();// assert something 16 } 17 18} 19
No verifiques tus pruebas a través de los stubs
Como ya mencionamos, un mock nos sirve para emular y examinar interacciones de salida, que generalmente producen side effects, los cuales pueden ser examinados como el resultado final.
Mientras que un stub es utilizado solo para satisfacer información o datos de entrada que necesita el SUT para producir un resultado, es decir los stubs no forman parte del resultado final.
En otras palabras podemos ver a los stubs como detalles de implementación, ya que no son parte del resultado final, recordando uno de los 4 pilares de las pruebas unitarias que es la resistencia al refactoring, no debemos acoplar las pruebas a detalles de implementación, si no verificar el resultado final.:
Para satisfacer el pilar de resistencia al refactoring, no debemos acoplar las pruebas a detalles de implementación, si no verificar el resultado final.
El verificar las pruebas con los stubs incurre en un antipatrón bien conocido, además cuando construimos un stub nosotros conocemos que información será devuelta en que escenario, así que verificar una prueba con un stub solo caería en una sobre especificación.
1// stub 🤖 2public class Tests { 3 @Test 4 public void an_example_test(){ 5 // Arrange 6 Country[] countries = new Country[1]; 7 countries[0] = new Country("Mexico") 8 CountriesApi api = mock(CountriesApi.class); 9 when(api.getAvailables()).thenReturn(countries) 10 UserController sut = new UserController(api); 11 // Act 12 sut.doSomething() 13 // Assert ❌ No verificar con stubs | 😖 sobre especificación 14 verify(sut, times(1)).getAvailables(); 15 assertEquals(sut.api.getAvailables()[0], countries[0]) 16 } 17} 18
Usando mocks y stubs juntos
Muchas veces podemos generar un test double que cumpla la función de un mock y un stub al mismo, para fines prácticos y por complejidad se determina que es un mock, veamos un caso de práctico:
1public class Tests { 2 @Test 3 public void register_seat_if_is_available(){ 4 // Arrange 5 Seats seats= mock(Seats.class); 6 7 // 🤖 Stub 8 when(seats.isAvailable(1)) 9 .thenReturn(true); 10 // 👾 Mock 11 when(seats.register("Jhon", 1)) 12 .thenReturn(true); 13 SeatsController sut = new SeatsController(database); 14 // Act 15 sut.register("Jhon",1); 16 // Assert 17 verify(seats, times(1)).register(); 18 } 19} 20
En el código anterior vemos cómo se utiliza un mock de la clase Seats como stub para satisfacer que un asiento esté disponible y un mock para verificar el registro del asiento.
¿Cómo se relacionan los mocks y stubs con el patrón de commands and queries?
Existe otra forma para determinar cuándo podemos realizar un mock y cuando se debe realizar un stub, en realidad esto empata con un patrón bien conocido llamado commands & queries.
En un resumen muy breve, este patrón trata de que los métodos u operaciones que tienen un efecto secundario o side effect sobre algo son conocidos como comandos mientras que los métodos que solo devuelven información a través de un cálculo o no sin generar un side effect, son queries.
Es un concepto también utilizado en las técnicas de refactor donde debemos tener bien separados las acciones que representan un comando y las que representan un querie, cada una en su propio método.
Lo anterior ayuda a una mejor base de código, facilidad de crear pruebas unitarias y para este caso la facilidad de seleccionar el test double correcto.
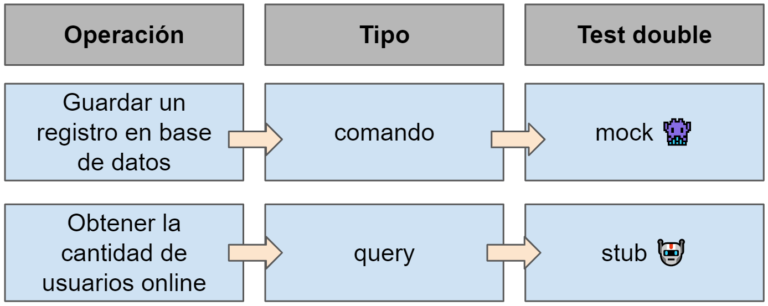
Comportamiento observable vs detalles de implemenación
Recordando el post de los 4 pilares de una prueba unitaria, vimos que la resistencia al refactoring es un pilar que se tiene o no se tiene, y que es este el que nos ayuda a evitar la fragilidad en las pruebas.
La forma de tener esta resistencia al refactoring es evitar la mayor cantidad de falsos positivos, es decir, concentrarnos en el que y no en el cómo, dicho de una forma más concreta, no debemos verificar nuestras pruebas a través de detalles de implementación si no con el resultado final.
El API pública debe exponer el comportamiento observable solamente
Todo software puede ser categorizado en 2 dimensiones:
- Api publica vs API privada
- Comportamiento observable vs detalles de implementación
Cada una de las categorías son mutuamente excluyentes, es decir, un método público no puede ser privado y viceversa, así como también el código puede ser un detalle interno de implementación o parte del comportamiento observable pero no ambos.
Muchos lenguajes de programación, de los más comunes los orientados a objetos, tienen mecanismos para poder hacer esta separación de categorías adecuadamente, como por ejemplo, modificadores de acceso : public y private.
Public por ejemplo, se utiliza para denotar que el método o miembro de un módulo o clase está expuesto para que lo utilice un cliente, es decir se puede acceder a el, mientras que private denota que es un método o miembro que solo puede ser accedido internamente en la clase o módulo, quedando oculto para clientes externos.
¿Cómo podemos distinguir que código forma parte del comportamiento observable y que es un detalle de implementación?
Un parte de código forma parte del comportamiento observable cuando:
- Expone una operación que ayuda al cliente a llegar a una de sus metas, puede o no incurrir en un side effect.
- Expone estado que ayuda al cliente a llegar a una de sus metas.
Cualquier otra parte de código que no cumpla con esto, es un detalle de implementación, que algo sea parte del comportamiento observable depende de quién sea el cliente y que tenga al menos una conexión directa con una de sus metas.
¿A qué nos referimos como el cliente? Puede referir a muchas cosas dependiendo donde reside el código, puede ser desde un miembro del mismo sistema, es decir una clase que consuma un método de otra clase, una aplicación externa o hasta la interfaz de usuario.
Idealmente un sistema con un API bien diseñada, alinea su API pública solamente a su comportamiento observable, dejando los detalles de implementación ocultos a los ojos del cliente.
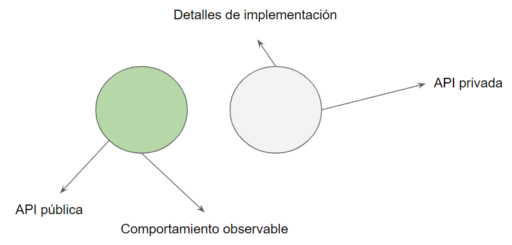
Por otro lado cuando un api no está bien diseñada, suele filtrar detalles de implementación a través del AP pública.
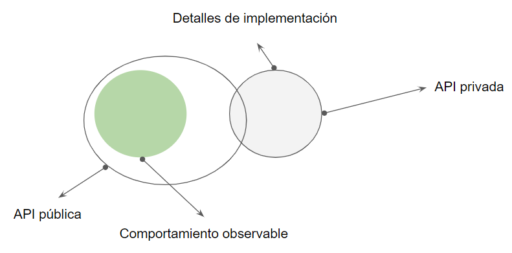
Exponiendo detalles de implementación 😱
Expliquemos cuál sería una forma de filtrar detalles de implementación al api pública:
1// Book.java 📂 2public class Book { 3 4 public int id; 5 public Date publicationDate; 6 public int category; 7 8 public Book(int id, Date publicationDate){ 9 this.id = id; 10 this.publicationDate = publicationDate; 11 } 12 13 public int categorize(Date publicationDate, Date lastCentury){ ❌ 14 return this.publicationDate.after(lastCentury) ? 0 : 1; 15 } 16} 17 18
1// BookController.java 📂 2public class BookController { 3 public void saveBook(int bookId, Date publicationDate){ 4 Book book = new Book(bookId,publicationDate); 5 Date lastCentury = new Date(1900, 1, 1); 6 book.category = book.categorize(publicationDate, lastCentury); ❌ 7 save(book); 8 } 9} 10
En el ejemplo anterior vemos cómo BookController es cliente de la clase Book, ya que está consumiendo elementos expuestos por esta misma, vemos que se guarda un libro con su id, su fecha de publicación y su categoría.
También vemos que para guardar el libro se calcula su categoría, pero hacerlo de esta manera puede generar inconsistencias, ya que si nosotros guardamos sin calcular esta categoría, java por defecto pondrá la categoría en 0 (defaults de datos primitivos en java) sin importar si es correcto.
Lo anterior demuestra que el cálculo de la categoría debería ser un detalle de implementación oculto para el cliente, a través de una buena encapsulación, asegurandonos no caer en una invariación.
Veamos un mejor enfoque de esto:
1// Book.java 📂 2public class Book { 3 4 private int id; 5 private Date publicationDate; 6 private int category; 7 8 public Book(int id, Date publicationDate){ 9 this.id = id; 10 this.publicationDate = publicationDate; 11 this.category = this.categorize(publicationDate) ✅ 12 } 13 14 private int categorize(Date publicationDate){ 15 Date lastCentury = new Date(1900, 1, 1); 16 return this.publicationDate.after(lastCentury) ? 0 : 1; 17 } 18 19 // getter methods ... 20} 21
1// BookController.java 📂 2public class BookController { 3 public void saveBook(int bookId, Date publicationDate){ 4 Book book = new Book(bookId,publicationDate); ✅ 5 save(book); 6 } 7} 8 9
En el anterior ejemplo vemos que el cálculo de la categoría ahora es invisible para el cliente y siempre será calculada correctamente.
Un API bien diseñada esta directamente relacionada con la encapsulación, recordemos que la encapsulación es la forma de protegernos de posibles inconsistencias o invariaciones.
La encapsulación también nos va a ayudar con la complejidad de nuestro sistema, si nosotros solo exponemos lo necesario para el cliente, sin filtrar detalles de implementación, será más fácil de entender qué es lo que hace nuestro módulo.
Con lo anterior, en relación directa, nos ayuda con la mantenibilidad de nuestros sistema y nos facilita hacer pruebas unitarias, ya que sabríamos directamente que estamos probando el comportamiento observable solamente.
La relación de los mocks y la fragilidad en las pruebas
Para finalizar este post, quiero resaltar que el libro contiene un par de temas mas sobre la relación de los mocks y la fragilidad en las pruebas, explica 3 cosas principalmente:
Habla sobre la arquitectura hexagonal, imaginando un hexágono, la parte interna o núcleo del hexágono representa la capa de dominio o lógica de negocio, y la parte externa representa una capa de aplicación que sirve para alimentar la capa de dominio y comunicarse con el mundo exterior.
La capa de negocio es la encargada de realizar el conjunto de operaciones que resuelve el problema para la cual esta hecha tu aplicación, mientras que la capa de aplicación expone como salidas estos resultados.
La capa de aplicación se comunica con el mundo externo con otros sistema o aplicaciones que pueden ser representados también con hexágonos.
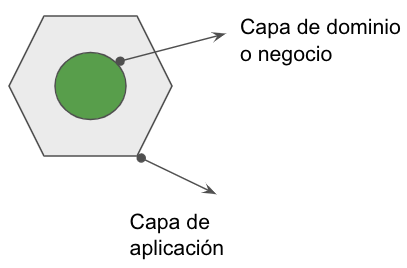 Arquitectura hexagonal
Arquitectura hexagonal
El concepto de este tipo de arquitectura hace una demostración de cómo se comunica una aplicación:
- 1️⃣ Internamente entre los elementos de la capa de negocio, estos son meros detalles de implementación y operaciones.
- 2️⃣ De la capa de negocios a la capa de aplicación, se entregan resultados, los cuales son comportamientos observados
- 3️⃣ De la capa de aplicación hacia fuera, ya es el resultado final el que se comunica a otros sistema u otras aplicaciones
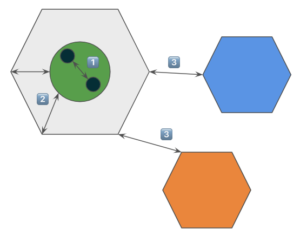 Comucación en la arquitectura hexagonal
Comucación en la arquitectura hexagonal
En el tipo 1️⃣ como ya hemos estudiado, los detalles de implementación no deben ser candidatos a ser mocks ni a tomarlos como base para la verificación de las pruebas.
En el tipo 2️⃣ son justamente las interacciones que deben se verificadas en nuestras pruebas unitarias.
Por último en el tipo 3️⃣ estan las interacciones candidatas a que se les sustituya por un mock, ya que tienen un side effect y forman parte del comportamiento observado, ya que estan ayudando a llegar a una de sus metas a otros clientes.
Como nota final recordemos que para evitar fragilidad en las pruebas, debemos verificar el comportamiento observado, las interacciones de salida, el resultado final que ayuda a llegar a una de sus metas a un cliente.
Entraré en más detalle en próximos capítulos de este post que es un resumen y mi entendimiento del libro:
📖 Unit testing: principles, pratices and patterns” por Vladimir Khorikov de la editorial Manning.