Estilos de pruebas unitarias
Esta vez conoceremos 3 estilos de realizar pruebas unitarias: output-based, state-based y communication-based, es decir, estilo basado en las salidas o resultado, el estilo basado en el estado y el estilo basado en las comunicaciones.
El estilo que ofrece la mayor calidad de pruebas es el basado en salidas, aunque desafortunadamente no puede ser utilizado absolutamente en todos lados, ya que este estilo depende de que lo que se esté probando este escrito en manera puramente funcional.
Debemos apoyarnos también de los otros estilos, sin embargo es posible orientar y convertir la mayor cantidad de código de nuestra aplicación a programación funcional para intentar mantener nuestras pruebas en el primer estilo.
A continuación explicaré más a detalle todo lo anterior.
Estilo output-based o estilo basado en resultados
El primero de los 3 estilos, en este estilo el sistema bajo pruebas es alimentado por una o más entradas conocidas y se verifica a través de la única salida que produce.
Este estilo solo aplica para cuando el SUT no cambia el estado interno o global de nada, simplemente la única salida generada es a través de su valor de retorno.
1// DiscountCalculator.java 📂 2 3public class DiscountCalculator{ 4 public double wholesaleDiscount(Product[] products){ 5 double disccount = products.length * 0.01; 6 return Math.min(disccount, 0.05); 7 } 8} 9 10// Product.java 📂 11public class Product { 12 private String name; 13 public Product(String name){ 14 this.name = name; 15 } 16} 17
Este es un ejemplo bastante sencillo, el método wholesaleDiscount de la clase DisccountCalculator recibe una lista de objetos de la clase Product, y multiplica la cantidad de esos productos en la lista por 1% para calcular el descuento, con un descuento máximo de 5% el cual es devuelto.
Y ya está no hay más, no hay efectos secundarios, no se almacenó nada en base de datos , el file system o algo por el estilo, aplicando una prueba unitaria quedaría como sigue:
1@Test 2public void disccount_of_product_list_with_max_5_percent(){ 3 // Arrange 4 Product[] products = { 5 new Product("soap"), 6 new Product("jam"), 7 new Product("water"), 8 new Product("soda"), 9 new Product("bread"), 10 new Product("toast") 11 }; 12 13 DisccountCalculator calculator = new DiscountCalculator(); 14 // Act 15 double disccount = calculator.wholesaleDiscount(products); 16 // Assert 17 assertEquals(disccount, 0.05); 18} 19
Este estilo también es conocido como funcional, y tiene sus raíces en la programación funcional, que busca o prefiere tener código sin efectos secundarios, de nuevo reitero este estilo debe ser el preferido, sin embargo no siempre va a ser posible aplicarlo.
Estilo state-based o estilo basado en estado
Este estilo busca verificar el estado del sistema después de haber realizado una operación completa.
El estado que verifica puede ser del SUT mismo, el estado global, el de uno de los colaboradores o incluso el de dependencias out-of-process como la base de datos o el sistema de archivos.
Ejemplo:
1// course.java 📂 2public class Course { 3 4 private ArrayList<Student> students = new ArrayList<Student>(); 5 public void addStudent(Student student){ 6 this.students.add(student) 7 } 8 public ArrayList<Student> getStudents(){ 9 return this.students 10 } 11} 12 13@Test 14public void add_student_to_a_course(){ 15 // Arrange 16 Course course = new Course(); 17 Student student = new Student("Andrew") 18 // Act 19 course.addStudent(student) 20 // Assert 21 assertEquals(course.getStudents().size(), 1) 22} 23
En el ejemplo anterior vemos que se está verificando a través del estado en el que se encuentra un atributo de la clase Course y utilizando uno de sus colaboradores, el método que se prueba no retorna nada, pero sí tiene una salida reflejada en el estado de la clase.
Estilo communication-based o estilo basado en comunicaciones
El último de los 3 estilos, es es el estilo basado en comunicaciones que verifica las pruebas a través de las interacciones de salida entre el SUT y sus colobadores.
Para verificar las interacciones de salida, recordemos que se utilizan los mocks, como dato adicional, el enfoque tradicional prefiere el estilo basado en estado que el de comunicaciones y viceversa la escuela de Londres.
1@Test 2 public void save_user_with_email(){ 3 // Arrange 4 User user = new User("ccodelapps@gmail.com"); 5 Database database = mock(Database.class); 6 when(database.save(user)).thenReturn(true) 7 UserController sut = new UserController(api); 8 // Act 9 sut.save(user) 10 // Assert 11 verify(database, times(1)).save(); 12 } 13
En el ejemplo anterior se verifica la interacción de salida que tiene el sistema bajo pruebas hacia la base de datos, se está comunicando y se verifica que se haya efectuado dicha comunicación.
Comparando los 3 estilos
Con el pilar de protección contra regresiones y la rápida retroalimentación
Esta es la comparación más simple por que en realidad ninguno de los 3 estilos provee una ventaja sobre otro para estos 2 pilares, recordemos que para tener el pilar de protección contra las regresiones necesitamos lo siguiente:
- 📝 La cantidad de código que se ejecuta durante la prueba
- 🕹 La complejidad del código que se está ejecutando
- 👓 La significancia del código ejecutado
En general tu puedes ejecutar tanto o tan poco código tu desees en tus pruebas ,lo mismo para la complejidad y la significancia, solo existe una diferencia en el estilo basado en comunicaciones, si abusas mucho de este estilo y por ende de los mocks, podrias terminar com pruebas superficiales.
Respecto a la rápida retroalimentación, de igual manera no depende de un estilo en particular, dependerá en si que aisles tus pruebas de dependencias out-of-process.
Con el pilar de resistencia al refactoring
En general las pruebas deben ser capaces de soportar si los detalles de implementación cambian, por tanto las pruebas no deben estar acopladas a estos, sino a los resultados.
Dicho lo anterior, nos damos cuenta que el primer estilo output-based o estilo basado en salidas es el que mejor resistencia al refactoring presenta ✅, ya que este tipo de pruebas se basa en los resultados.
El estilo basado en estado, es un poco mas propenso a tener falsos positivos, por tanto es menos resistente al refactoring, ya que se verifican elementos de la clase o colaboradores, entre más amplia o profunda se la verificación pas probabilidad hay de que se caigan en verificar detalles de implementación 😒.
Por último el estilo basado en comunicaciones, puede caer como ya dijimos en pruebas superficiales o frágiles si se abusa de los mocks, recordemos que los mocks solo deben ser para dependencias de fuera de la aplicación y que tengan un efecto secundario, por tanto este estilo es el más propenso a esto.
Con el pilar de mantenibilidad
El pilar de la mantenibilidad está altamente relacionado con los estilos de pruebas unitarias, pero a diferencia de la resistencia al refactoring no se puede hacer mucho al respecto, recordemos que las pruebas son mantenibles en medida de:
- 😱 Que tan dificil es entender las pruebas
- ✈ Que tan dificil es ejecutar las pruebas, si hay que levantar instancias de alguna otra cosa
Generalmente las pruebas output-based son cortas y concisas, lo cual las vuelve altamente mantenibles, y dado que este tipo de pruebas no genera efectos secundarios o de estado no se conecta a dependencias out-of-process lo cual las vuelve más rápidas también.
Para las pruebas basadas en estado suele tomar más líneas de código verificar las, ya que las pruebas basadas en este y el comportamiento que se esté probando puede generar más de un efecto secundario que se puede generar, esto se vuelve peor si no se encuentra bien encapsulado el comportamiento, así que son un poco menos mantenibles.
De nuevo (parece que es el peor , pero todavía puede usarse si se lo hace adecuadamente) es el estilo basado en comunicaciones, ya que debido al uso de mocks, dependiendo de qué complejos sean, si los combinamos con stubs y demás cosas, hace las pruebas mas grandes y más complejas de entender.
Conclusiones de la comparación
Hemos comparado cada uno de los estilos y su desempeño para cada uno de los 4 pilares de las pruebas unitarias, vimos que para la protección contra regresiones y la rápida retroalimentación califican igual.
En cuanto al pilar de resistencia la refactoring, el estilo output-based raramente va a estar acoplado a los detalles de implementación, las pruebas de este estilo son concisas y muy raramente van a utilizar dependencias out-of-process, por lo cual son muy rápidas de ejecutar.
El estilo stated-based y communication-based, suelen ser más propensas a caer en detalles de implementación y también suelen ser pruebas grandes con un costo más alto de mantenimiento.
Una vez entendido lo anterior, nos damos cuenta que siempre es preferible utilizar el estilo basado en salidas o output-based, sobre los demás, desafortunadamente para ello se necesita que lo que se prueba este escrito de manera funcional, pero esto no siempre es así, sin embargo sí podemos aplicar ciertas técnicas para refactorizar la mayor parte del sistema y pruebas a este estilo.
| Output-based | State-based | Communication-based | |
|---|---|---|---|
| Resistencia al refactoring | ⭐⭐⭐ | ⭐⭐ | ⭐ |
| Mantenibilidad | ⭐⭐⭐ | ⭐⭐ | ⭐ |
¿Que es la programación funcional?
Como ya mencioné, el estilo de pruebas basado en salidas, es posible solo si lo que se está probando está escrito en manera puramente funcional, para ello se utiliza la programación funcional.
La programación funcional, es la programación con funciones matemáticas o funciones puras, dichas funciones o métodos no deben tener ninguna entrada o salida oculta, todas deben estar a la vista, es decir, tienen que ser explícitas o expresadas, también una función de este tipo, va a producir el mismo resultado para las mismas entradas siempre.
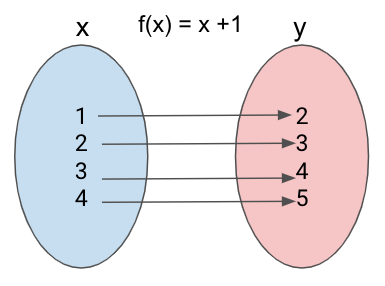 Programación funcional
Programación funcional
Una función matemática simple, donde por cada valor en x hay uno en y. En la programación esto se expresa a través de la firma o declaración del método, debe tener una lista de parámetros definida, el nombre del método, el tipo y valor de retorno.
Recordemos que un cambio de estado o una interacción de salida también son tipos de salidas, pero para este tipo de funciones, la única salida que debe existir es la que retorna el método.
 Partes de una función
Partes de una función
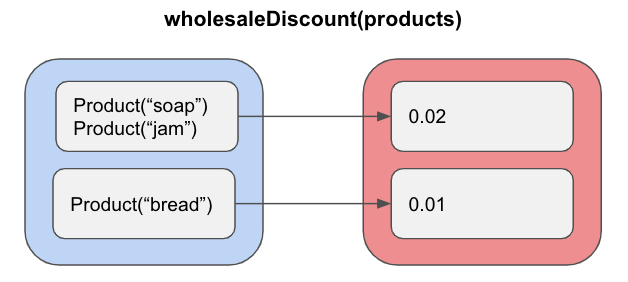
Recapitulando un poco, en el estilo output-based las entradas y salidas deben ser totalmente explícitas y a la vista, representadas por los parámetros que reciben y el valor de retorno que dan, no más, sin embargo existen más tipos de entradas y salidas ocultas que pueden hacer tu código un poco más complejo y menos estable, algunas de estas son:
- 🧪Side effects o efectos secundarios, estos no son expresados en la firma del método, mutan el estado de la clase, de un archivo, etcétera.
- ⚠️Excepciones, cuando dentro de la ejecución de un método alguna instrucción puede lanzar una excepción, esta crea una salida distinta que puede o no pasar.
- 🕹 Referencia interna o externa, estas son un tipo de entrada oculta, cuando el método accede a algún valor de la clase, de la base de datos de manera interna.
Como regla general para determinar si un método es funcional o similar a una función matemática, se debe sustituir fácilmente su llamado por un valor que devolvería y esto no debe cambiar el funcionamiento de tu sistema o programa, por ejemplo,en lugar de invocar wholesaleDiscount con una lista de 2 productos puedo utilizar el valor que devolvería ➡️ 0.02.
¿Que es una arquitectura funcional?
A pesar de las bondades y practicidad que tiene escribir tu sistema en manera, no se puede escribir todo un sistema de esta manera, es decir, no se puede crear una aplicación que no incurra en ninguna side effect, sería totalmente impráctica.
Después de todo una aplicación trata de eso, de guardar la información de usuarios, registrar ordenes, compras , estadísticas, etcétera.
Por ello la meta de la programación funcional no es eliminar los side effects, sino separar la lógica de negocios del código que incurre en side effects, y es donde entra la arquitectura funcional.
La arquitectura funcional busca maximizar la cantidad de código escrito en manera puramente funcional y minimizar la que incurre en side effects, esta separación es por 2 tipos de código:
| Código que toma decisiones | Código que actua basado en esas desiciones |
|---|---|
| No requiere incurrir en side-effects y puede ser escrito como una función matemática (es inmutable) | Convierte las decisiones en cosas visibles, como cambios a la base de datos, el envío de un mensaje, etcétera (es mutable) |
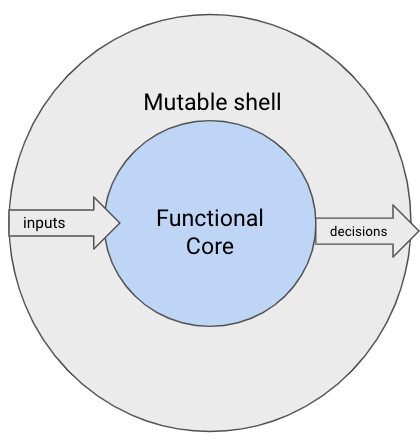 Esquema simple de la arquitectura funcional
Esquema simple de la arquitectura funcional
Podemos ver como la parte mutable ofrece las entradas al core funcional, que se encarga de calcular y procesar las decisiones, después estas las recibe de nuevo la parte mutable para efectuar las acciones visibles.
Ejemplo: Refactorización a arquitectura funcional para utilizar el estilo output-based
https://github.com/Andrew0914/transition_fa
Entraré en más detalle en próximos capítulos de este post que es un resumen y mi entendimiento del libro:
📖 Unit testing: principles, pratices and patterns” por Vladimir Khorikov de la editorial Manning.