Refactorizando para tener pruebas unitarias valiosas
En el post 1 La meta de las pruebas unitarias 🧪, definimos cuáles son las tres características que definen a una buena prueba unitaria, la última de ellas: “Deben ofrecer el máximo valor con el mínimo de costo de mantenimiento“, pero para poder lograr esto necesitamos 2 cosas:
- 🧠 Reconocer que es una prueba valiosa y cuál no lo es
- ✍️ Escribir una prueba unitaria valiosa
En el post Los 4 pilares de una buena prueba unitaria vimos cómo reconocer una prueba unitaria valiosa, pero a lo largo de este post aprenderemos cómo se escriben ese tipo de pruebas, también necesitamos tener habilidades de diseño en nuestro código, ya que sería imposible hacer una prueba valiosa sin poner un poco de esfuerzo en escribir una buena base de código.
Identificar el código a refactorizar
Es casi imposible el mejorar una suite de pruebas sin refactorizar nuestra base de código mejorandola también, ya que la suite de pruebas está intrínsecamente conectada a esta base de código.
Los 4 tipos de código
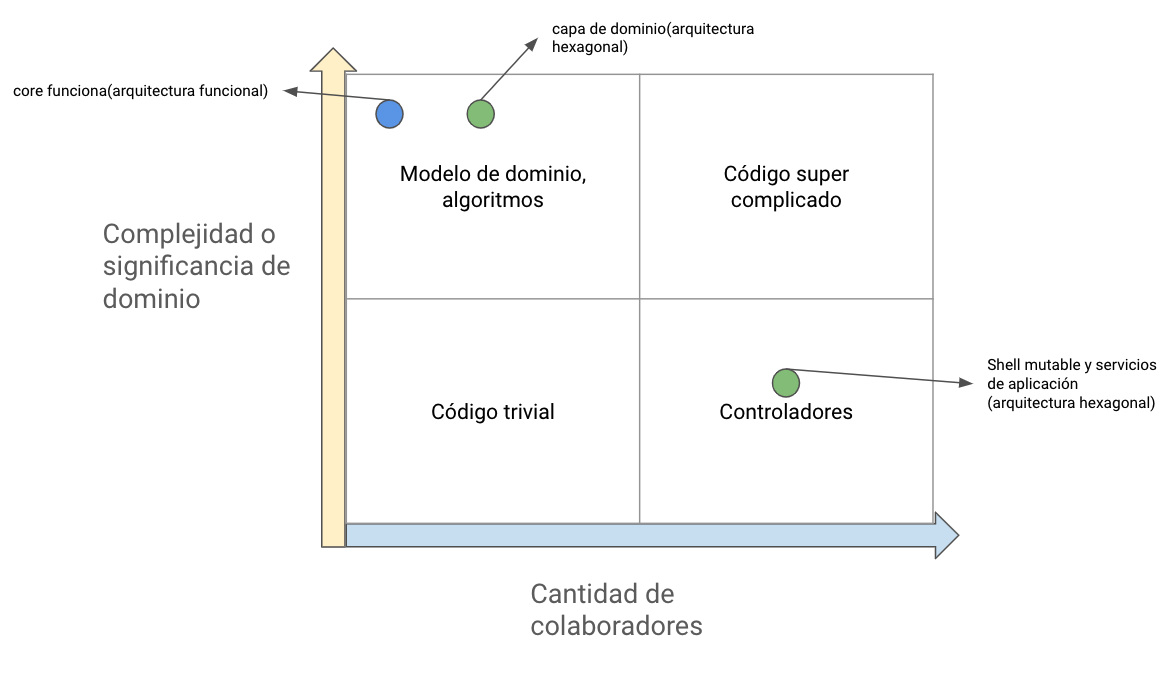
Podemos categorizar nuestro código en función de dos dimensiones:
- 🧩 Complejidad o significancia de dominio.
- 🙋♂️ Cantidad de colaboradores
La complejidad o significancia de domino est definida por la cantidad de decisiones o punto de ramificación que hay el código, mientras mayor sea este número mayor será la complejidad.
Ejemplo: si en tú código no hay ni una sola sentencia if o un loops, la complejidad se calcula de la siguiente manera: 1 + branching points, en este caso sería 1 + 0 = 1.
Ahora imaginemos que nuestro código tiene una sentencia if solamente, la complejidad sería de 1 + 1 = 2, si embargo aunque este es un punto de partida, no siempre el código complejo tiene significancia de dominio, y el código simple también puede tener significancia de dominio. La complejidad o significancia de dominio en el código está directamente relacionado con la meta del usuario final .
La segunda métrica que es la cantidad de colaboradores, como ya vimos en posts pasados un colaborador es una dependencia que puede ser mutable u out-of-process o las 2, un código con una gran cantidad de colaboradores puede generar pruebas grandes con una amplia y compleja maquinaria de mocks que inmediatamente eleva los costos en términos de mantenibilidad, por eso es importante tener separada nuestra lógica principal de las interacciones y solo aplicar mocks para las interacciones que están fuera de los límites de nuestro sistema.
La combinación de estas 2 dimensiones nos muestra que existen 4 tipos de código:
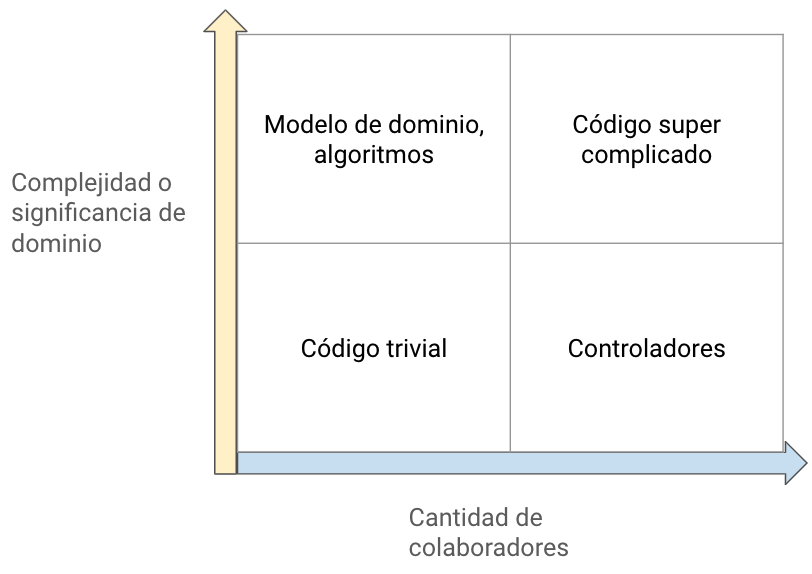 4 tipos de código
4 tipos de código
- 🧠 Modelo de dominio o algoritmos: es el código que resuelve la meta final del usuario, suele ser complejo pero no siempre ya que puede haber algoritmos complejos que no aportan directamente al modelo de dominio.
- ✏️ Código trivial: este tiene muy pocos colaboradores o ninguno y no tiene relevancia, puede ser por ejemplo la declaración de un constructor.
- 🚀 Código super complicado: tiene una alta complejidad y un alto número de colaboradores, por ejemplo un fat-controller, donde se ponga toda la lógica e interacciones.
- 🕹 Controladores: no tiene lógica de negocio crítica o significativa pero se encarga de coordinar el trabajo de otros componentes , como las clases de modelo y aplicaciones externas.
Esto nos da como conclusión que el código que se categorize en el cuadrante superior izquierdo, nos da la oportunidad de generar pruebas de mayor valor y menos costosas, dándonos una mayor protección contra las regresiones y bajos costos de mantenibilidad.
Al código trivial casi siempre no vale la pena hacerle pruebas unitarias, ya que el valor que aportan es casi 0.
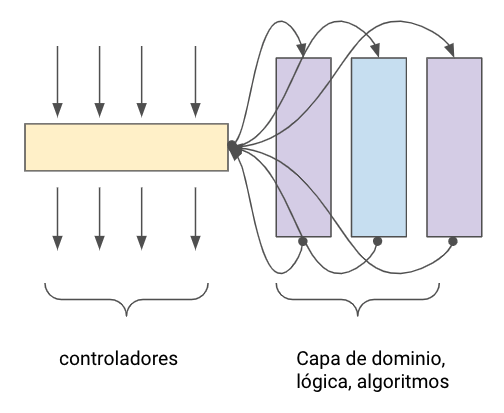
El cuadrante más problemático, el del código super complicado, es bastante difícil de probar pero muy riesgoso el no hacerlo, este tipo de código en un sistema es realmente la razón por la cual muchas personas abandonan el hacer pruebas unitarias, pero no se preocupen, si hay una forma de lidiar con este tipo de código, es dividirlo en 2 partes: controladores y algoritmos.
Una vez que se hace esta división, nos enfocamos en los algoritmos para solo obtener pruebas valiosas, si bien no alcanzaremos un 100% de coverage, recordemos que este no es nuestro objetivo sino tener una suite de pruebas que aporte el mayor valor posible.
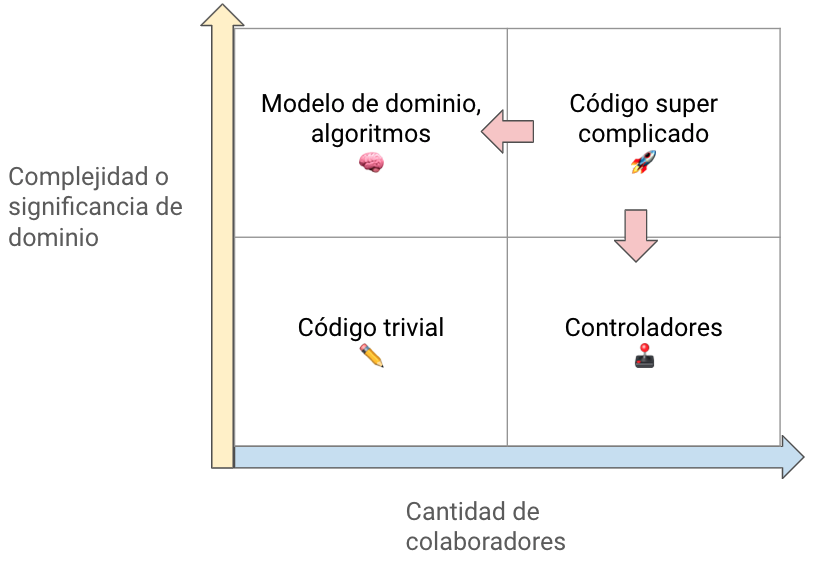 Estrategia para el código super complicado
Estrategia para el código super complicado
Usando el patrón Humble-object para dividir código super complicado.
A menudo nos encontramos con código que es muy difícil de probar por qué porque está muy acoplado a las dependencias de un framework, por ejemplo llamadas asíncronas o ejecuciones multi-thread, interfaces de usuario, comunicación con dependencias out-of-process y más.
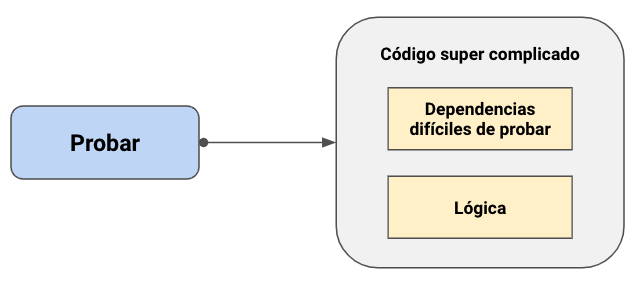 Patrón humble
Patrón humble
Para poder probar necesitamos extraer la lógica importante o que tiene significancia de dominio del código con dependencias difíciles de probar, normalmente se mueve esta lógica a una clase nueva o archivo nuevo, el código con dependencias complicadas puede que conserve algunos detalles de lógica pero estos no deberían ser significativos para el dominio y por tanto no se necesita aplicarles pruebas.
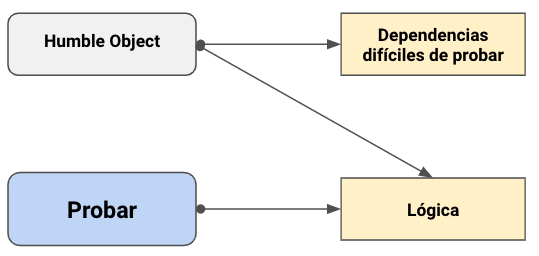 Patrón humble
Patrón humble
Podemos ver que ya hemos aplicado este patrón en ejemplos de post anteriores, específicamente: Mocks y fragilidad en las pruebas donde vemos que la arquitectura hexagonal busca separar la lógica de negocios de las comunicaciones con dependencias out-of-process,y en Estilos de pruebas unitarias vemos que la arquitectura funcional va todavía más haya separando la lógica de todas las dependencias o colaboradores no solo las out-of-process, por ello es que esta ultima es muy testeable.
 Ejes de arquitectura
Ejes de arquitectura
Otra forma de ver el patrón Humble object, es apegarse al principio de que cada componente en tu sistema debe tener una única responsabilidad, es decir, si una clase o módulo tiene lógica de negocio su única responsabilidad debe ser esa.
En resumen tenemos que separar la lógica de negocios del código de orquestación, también podemos ver el código en términos de amplitud(más amplio entre más colaboradores o dependencias) y profundidad(más profundo entre más importancia y complejidad).
 Amplitud y profundidad
Amplitud y profundidad
Es tan importante esta separación, que este patrón es aplicado a muchas de las arquitecturas más populares como: MVC (Model-View-Controller), MVP (Model-View-Presenter), donde el Controller y Presenter son controladores y a su vez son humble objects que orquestan y ayudan separar la lógica del modelo de la vista o UI.
Ejemplo: Refactorizando para obtener pruebas unitarias valiosas.
refactoring_toward_valuble_tests 👈 🔗
Entraré en más detalle en próximos capítulos de este post que es un resumen y mi entendimiento del libro:
📖 Unit testing: principles, pratices and patterns” por Vladimir Khorikov de la editorial Manning.